Выбор района для ювелирной мастерской в СПб: разбор по данным
Как я собрал и проанализировал данные из Росстата, визуализировал конкурентную среду на карте, построил скоринговую модель районов и признал, почему всего сделанного недостаточно для реального решения.
Контекст
Друг решил помочь своему знакомому, который хотел открыть ювелирную мастерскую в Санкт-Петербурге. Спросив меня, нет ли у меня желания покопать данные, вдруг мы сможем как-то помочь, на что я ответил “ДА”, давай копать!
На входе были координаты 354 существующих мастерских на начало 2025 года (из Яндекс.Карт), их статус (работает / закрыта), рейтинг, часы работы. Мне плохо представлялось с чего начать и к чему нужно прийти. Поэтому я сразу пустился в реализацию – не в первый раз идти вслепую, это весело!
- Стек: Python, Pandas, Folium, Plotly, GeoPandas, Google Sheets, Tableau
- Данные: Яндекс.Карты (организации), Росстат (население, зарплаты, ввод жилья, возрастная структура), OpenStreetMap (GeoJSON границ)
- Масштаб: 18 районов, 111 муниципальных округов, диапазон лет в данных 2018–2025 года
Артефакты
Часть 1. Череда тупиковых решений
Начал с очевидного – отобразить все организации на карте. Но не просто на карте, а именно в рамках СПб. Нашел на Github разметку в GeoJSON и это сильно выручило. Спасибо автору! Сверху набросал кластеризацию по организациям, тепловую карту, разделение на работающие и закрытые.
Кроме этого нашел плотность застройки вот тут что можно было тоже отобразить на карте. В легенде на карте она под пунктом “Плотность”.
На карте видно концентрацию в центре и вдоль основных магистралей. Но этого мне было мало. Мне стало интересно разделить город на районы и МО. Где-то на просторах интернета нашел разметку для разделения и дополнительно решил ограничить отображение только Петербургом, без карты мира. Это съело бы меньше ресурсов и выглядело бы чище.
В итоге мало что понятно, особенно с тепловыми картами, но внимание привлекает.
Для ограничения попробовал Plotly, Folium, KeplerGL, смотрел Mapbox. Остановился на Folium. Добился обрезки – но не так, как хотел. Карта всё равно грузится целиком, а сверху накладывается маска, скрывающая всё за пределами городской границы. При масштабировании это заметно.
Взгрустнул, двинулся дальше.
Интерактивный дашборд
Раз карта есть – почему бы не сделать в браузере дашборд с управляющими контролами и легендой, а потом оформить как сайт-визитку с результатами исследования?

И вот тут я снова столкнулся с проблемой: скрипт генерирует HTML с картой на Folium, которую я впоследствии вставляю через iframe в дашборд, по сути в другой HTML-файл. При таком подходе управлять контролами извне не получилось. Потратил день, понял что ни к чему толковому не пришёл. А рисовать прямо на карте используя Folium – у меня не хватило нервов, там стилизация показалась довольно сложной.
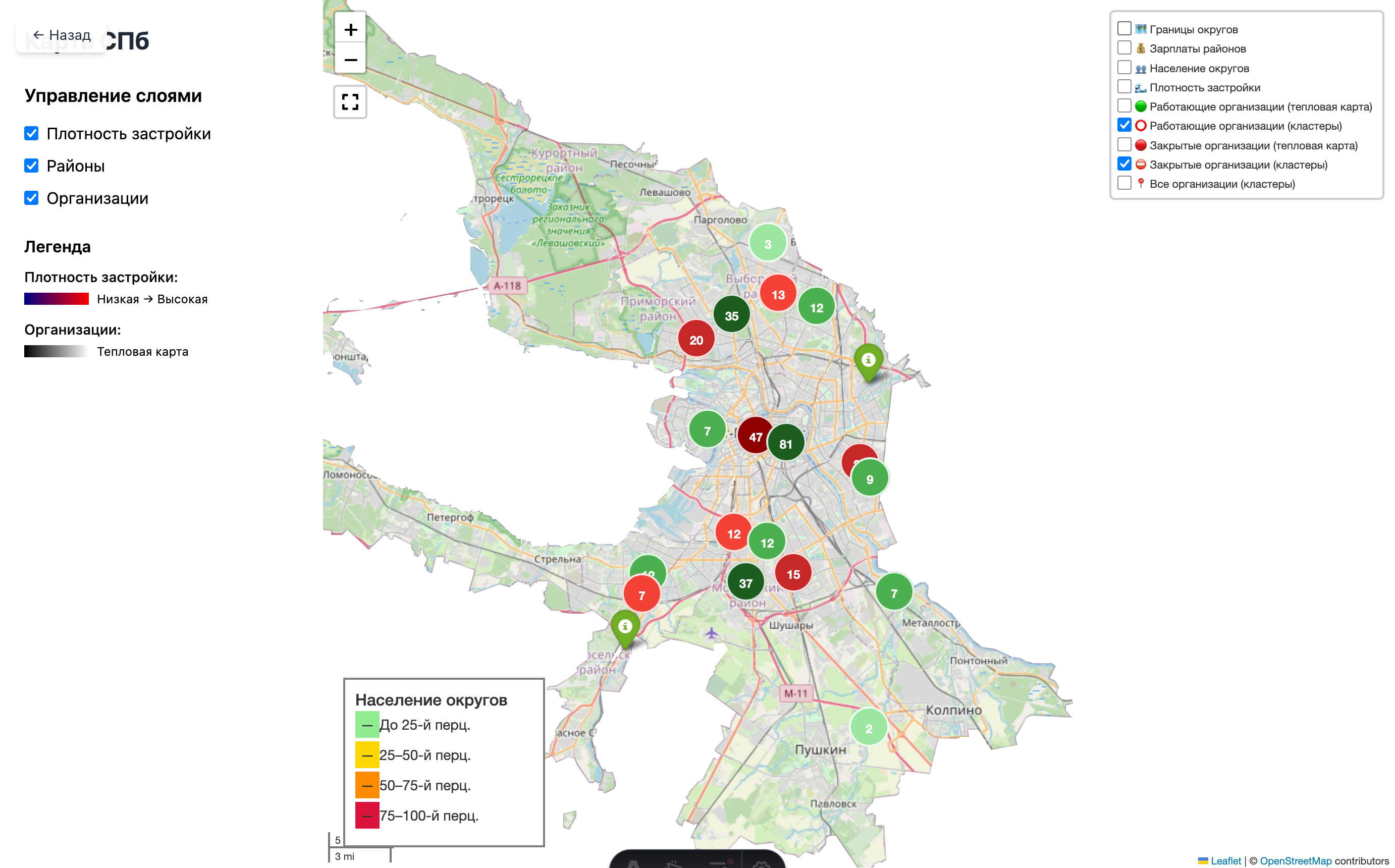
Посмотрел на результат и понял: идея с дашбордом не имеет большого смысла – есть Google Sheets и Tableau. Кроме того, я отклонился от цели.
Взял паузу…
Визуализация
Вспомнил что я неплохо адаптировался к работе с Plotly. Решил – почему бы снова не пойти в визуализацию.
Работал я исключительно с данными Росстата, а именно с количеством населения в районах и муниципальных округах. Вот что получилось:
Изменение населения районов и МО в СПб за 2018–2025 года
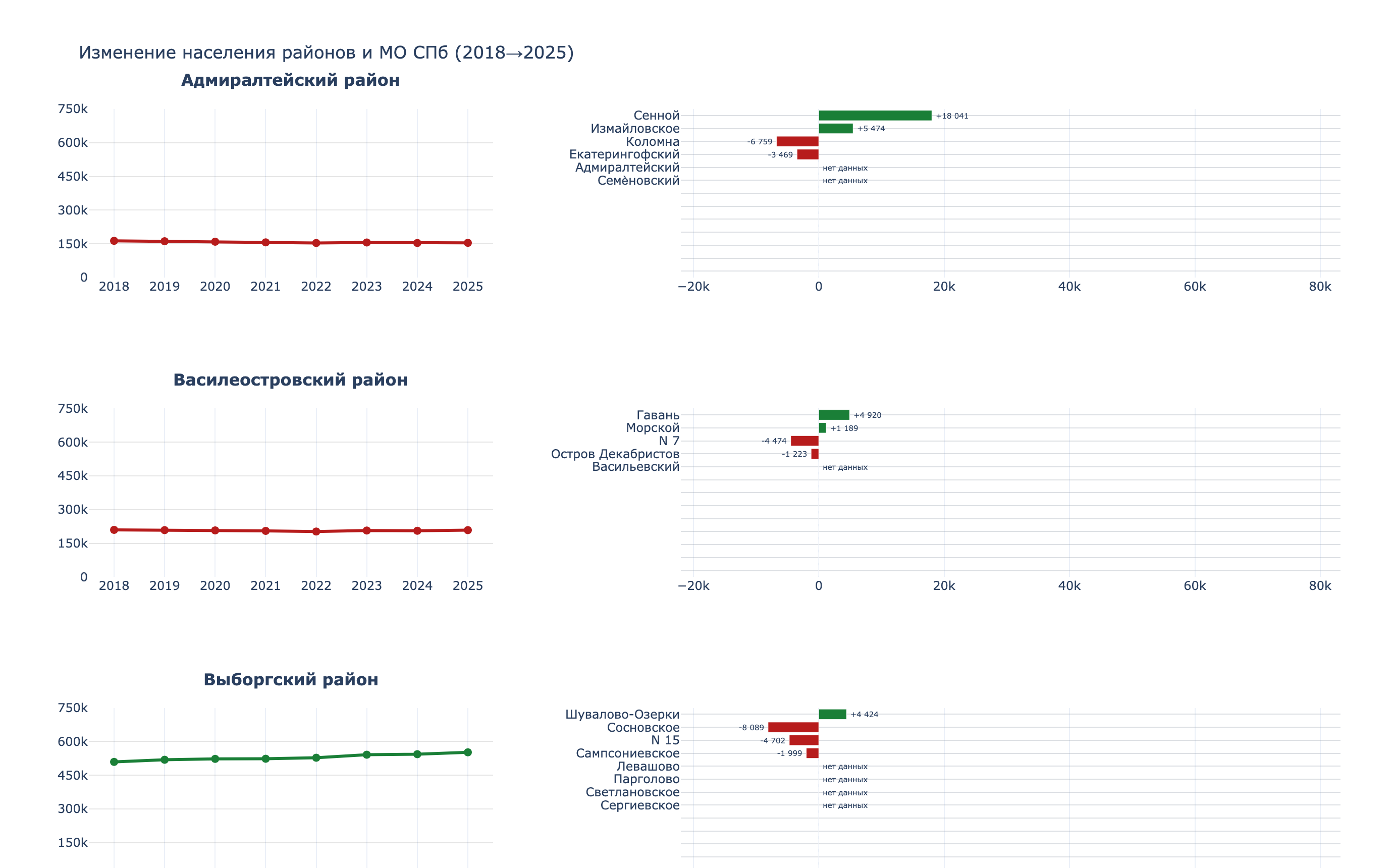
Этим графиков я в особенности горжусь. Правда на скрипт без боли не посмотришь…
Изменение населения МО в СПб за 2018–2025 года
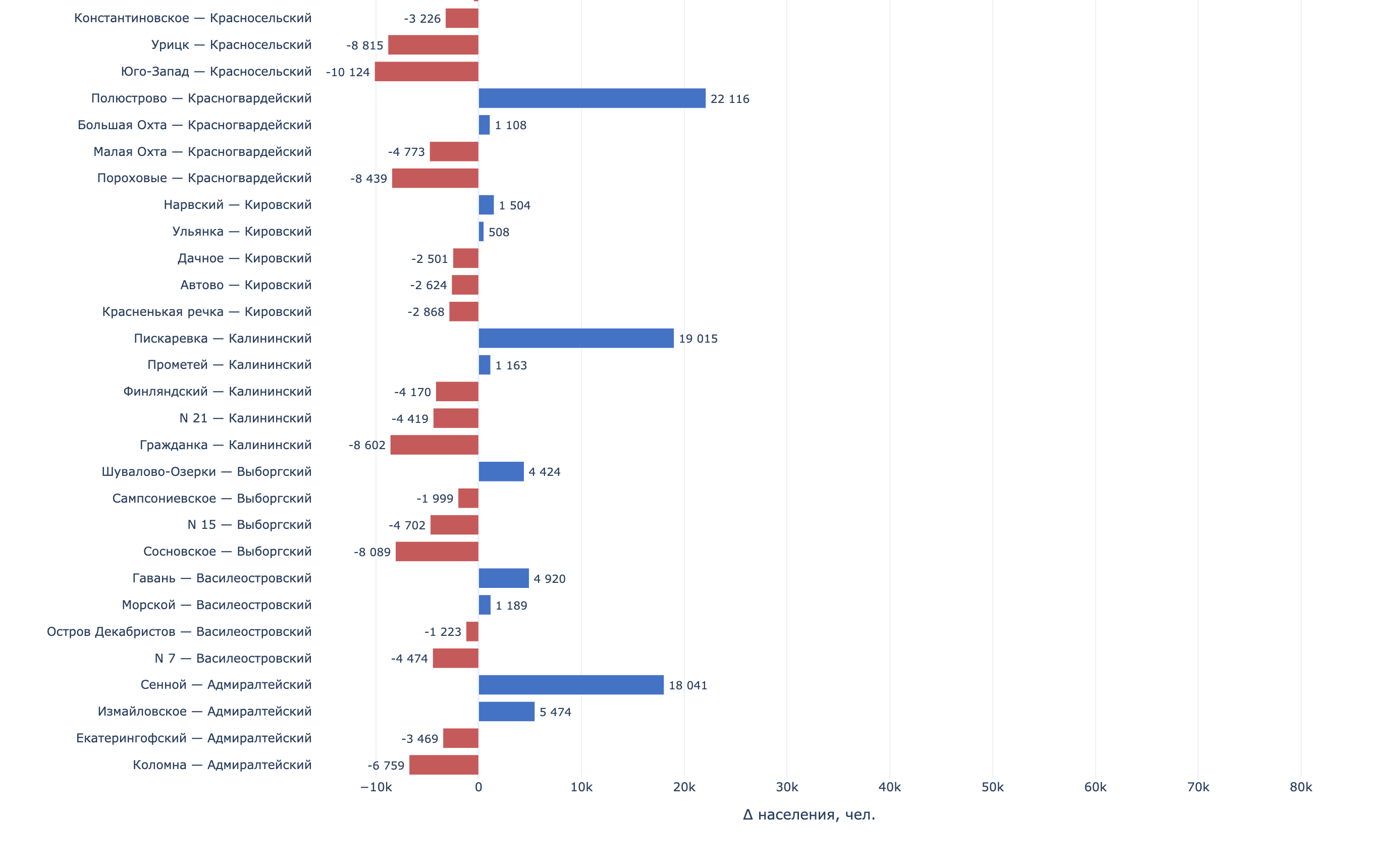
Изменение населения районов в СПб за 2018–2025 года
Компактный вид: население районов и МО
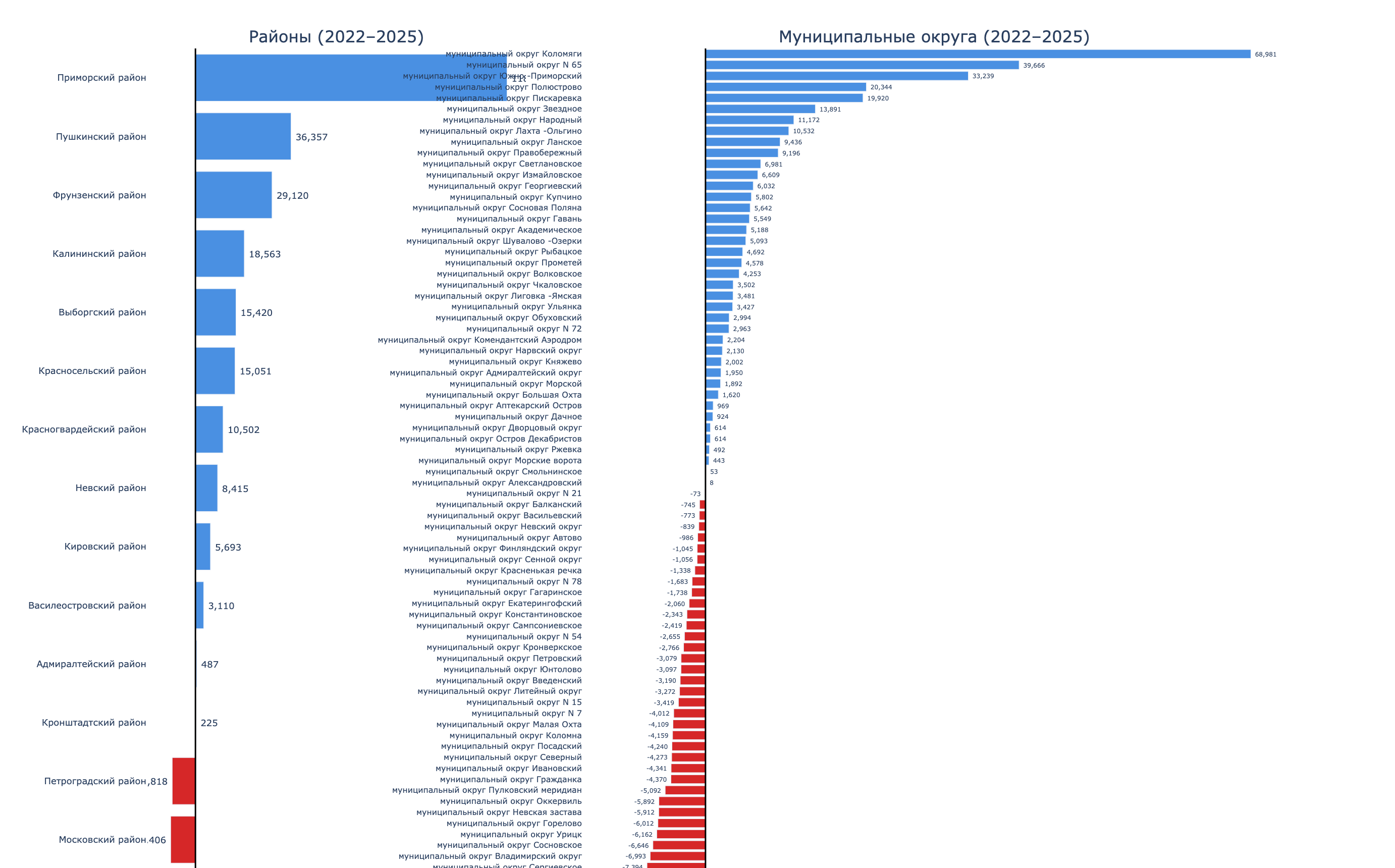
В общем, пробовал разные подходы. Вроде неплохо. Много потратил времени? Конечно! Пришёл в тупик? Конечно! Но зато попрактиковался в разработке графиков… И снова пришёл к выводу что это не масштабируемо и особо не переиспользуемо.
И вот я опять у разбитого корыта. Снова отклонился от цели. Погрустил.
Взял паузу…
Часть 2. От хаоса к методологии
После перерыва стало ясно – проблема не в инструментах, а в отсутствии плана. Я делал то, что умел, а не то, что нужно.
Параллельно начал проходить курс Google Data Analytics. Там я открыл для себя простой и мощный фреймворк:
Ask → Prepare → Process → Analyze → Share → ActЭто именно то, чего не хватало.

Я решил вернуться в начало и идти строго по шагам.
Что сделал по-другому
Профиль посетителя.
Вместе с «заказчиком» составили портреты посетителей: общий, для женщин, для мужчин. Это немного сузило пространство для поисков.
Утверждение этапов.
С другом договорились какие этапы точно стоит сделать, а на какие ресурсов в рамках текущего подхода просто не хватит. Таким образом ещё снизили объём, который предстояло исследовать.
Организация.
Убрал лишние скрипты, оставшиеся переименовал в порядке выполнения. Каждый скрипт получил описание: какие файлы читает, какие генерирует.

Структура данных.
До этого все скрипты были в папке scripts, без какой-либо нумерации. Искать их и отличать друг от друга было сложновато. Данные же все лежали в папке data точно так же как и скрипты - корзина с мусором…
Решил в новом подходе разделить на:
source/(исходники из Росстата и Яндекс.Карт)output/(итоговые CSV)report-md/(markdown-отчёты)

Документация.
Начал фиксировать источники данных и другую вспомогательную информацию для всех полученных результатов.

Следование первым трём этапам фреймворка помогло структурировать подход и выработать последовательность работы с данными. Поэтому перед самим анализом у меня ушло достаточно времени чтобы написать скрипты, обработать данные, описать вспомогательную информацию. Зато какой результат!
У меня получился набор CSV-файлов, связанных между собой через единый идентификатор. Это можно закидывать что в Google Sheets, что в Tableau и сразу анализировать.
Визуализация
Вместо того чтобы сразу прыгать в визуализацию, сначала загрузил все файлы в Google Sheets. Связал их, немного обработал и сделал первые графики. Этого было достаточно чтобы получить базовое понимание что у меня есть и что я могу из этого сделать.
Визуализации в Google SheetsПосле того как сделал графики, переделал их спустя время на Tableau, ради эксперимента и изучения второго! Тем не менее Google Sheets достаточно мощный чтобы делать многие расчёты и визуализации.
Часть 3. Что показали данные
После того как pipeline заработал, у меня на руках оказались связанные CSV-таблицы по уникальному id для четырёх направлений: конкурентная среда, демография, платёжеспособность и инфраструктура.
Конкурентная среда
Всего в базе 354 организации. Из них 219 работают (61.9%), 135 закрыты (38.1%). То есть больше трети мастерских не пережили рынок. Мастерские есть в 15 из 18 районов – три района (Кронштадтский, Курортный, Петродворцовый) не имеют ни одной точки, при том что их суммарное население – 264 тыс. человек.
Больше всего мастерских в Приморском (39), Центральном (37) и Невском (34). При этом у Приморского – худшая выживаемость среди крупных районов: только 48.7% мастерских работают, остальные закрыты. Для сравнения, в Кировском выживаемость – 76%, в Калининском – 74%.
Но количество мастерских само по себе мало что значит. Важнее – сколько жителей приходится на одну мастерскую. Этот показатель говорит о конкурентном давлении: чем больше людей на мастерскую, тем меньше конкуренция.
Разброс огромный. В Колпинском – 190 тыс. жителей на одну мастерскую (фактически монополия). В Пушкинском – 69 тыс. В Приморском – 37 тыс. А в Центральном и Петроградском – менее 10 тыс. на точку, рынок перенасыщен.
На уровне МО картина ещё контрастнее. «Белые пятна» – округа с крупным населением и нулём мастерских:
| Муниципальный округ | Район | Население |
|---|---|---|
| Колпино | Колпинский | 147 179 |
| Коломяги | Приморский | 122 082 |
| Пушкин | Пушкинский | 108 969 |
| Светлановское | Выборгский | 90 456 |
| Петергоф | Петродворцовый | 81 767 |
| Ланское | Приморский | 70 883 |
| Красное Село | Красносельский | 61 162 |
| Юго-Запад | Красносельский | 58 269 |
При этом в центре – обратная история. В МО «N 78» (Центральный район) на одну мастерскую приходится всего 2 986 человек, на Аптекарском Острове – 3 515. Конкуренция максимальная.
Демография
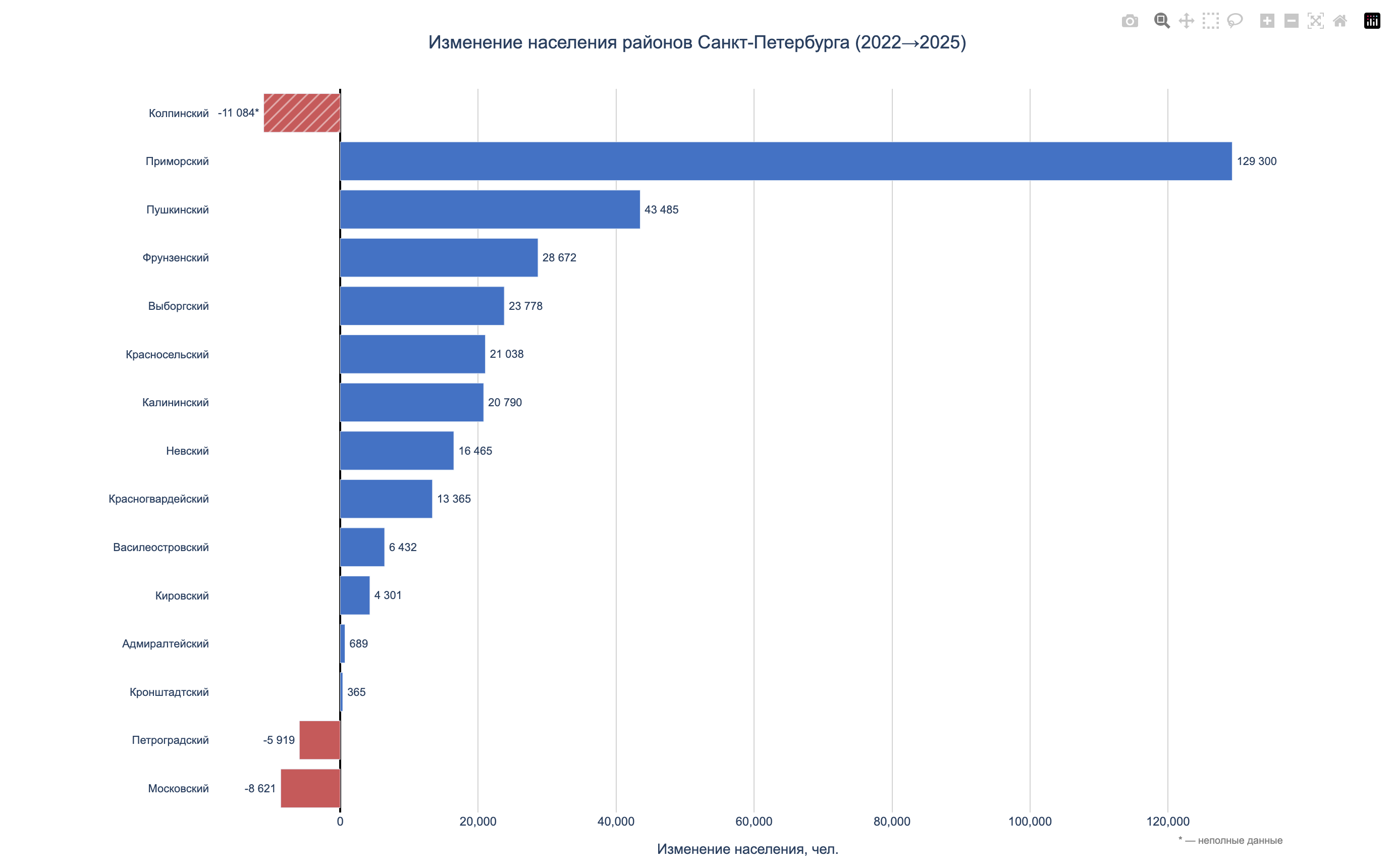
Данные о населении за 2018–2025 показали два разнонаправленных тренда. Часть районов активно растёт за счёт новостроек, часть – стабильно теряет жителей.
Лидеры роста – Пушкинский (+32.9%, прибавил 69 тыс. человек за 7 лет), Приморский (+26.4%, +149 тыс.) и Красносельский (+15.1%, +58 тыс.). На другом полюсе – Петроградский (−12.3%), Центральный (−10.5%) и Адмиралтейский (−5.6%).
На уровне МО внутри растущих районов рост неравномерный. Например, в Приморском районе Коломяги выросли на 163%, Лахта-Ольгино – на 263%, а Озеро Долгое наоборот потеряло 7%. В Красносельском Южно-Приморский прибавил 73%, а Юго-Запад и Урицк потеряли по 15%.
Из возрастной структуры за 2024 год вытащил целевую аудиторию – людей 30–65 лет. Это основные клиенты мастерских по ремонту: работающие люди с украшениями, которые нуждаются в обслуживании.
Крупнейшая целевая аудитория – в Приморском (379 тыс. человек 30–65 лет), Невском (293 тыс.), Калининском (281 тыс.) и Выборгском (279 тыс.). Самая маленькая – в Кронштадтском (22 тыс.) и Курортном (43 тыс.).
Отдельно посмотрел на женскую аудиторию трудоспособного возраста – женщины обращаются в мастерские чаще и нередко приносят несколько изделий за визит.
По абсолютным числам лидирует Приморский (216 тыс.), за ним Калининский (166 тыс.) и Невский (164 тыс.).Доля женщин трудоспособного возраста от общего населения района при этом довольно ровная – от 27% до 31% по всем районам, без явных выбросов.
Платёжеспособность и инфраструктура
Средняя зарплата по районам – это зарплата на предприятиях, зарегистрированных в районе, а не доход жителей. Но даже с этой оговоркой разброс заметный: от 108 531 ₽ в Красносельском до 166 640 ₽ в Приморском.
Правый верхний квадрант — самые интересные районы: высокая зарплата и низкая конкуренция. Левый нижний — наименее приоритетные.
Несколько районов заметно выделяются вверх по оси Y — это означает очень высокое значение people per workshop, то есть особенно низкую обеспеченность мастерскими.
Районы, расположенные правее, имеют более высокий уровень дохода.
Самые перспективные точки — те, что находятся ближе к правому верхнему углу, особенно если у них ещё и крупный пузырь, то есть большой рынок.
Интересное наблюдение: высокая зарплата не коррелирует с количеством мастерских. Московский район (163 332 ₽) и Приморский (166 640 ₽) – лидеры по зарплатам, но при этом Московский перенасыщен мастерскими (21 штука на 334 тыс. населения, то есть ~16 тыс. на точку), а Приморский – нет (19 на 715 тыс., ~38 тыс. на точку).
По вводу жилья за 2021–2023 абсолютный лидер – Приморский (2 479 тыс. кв. м), далее Выборгский (1 384) и Невский (1 008). Это косвенный индикатор притока нового населения в ближайшие годы.
Для сравнения: в Кировском за три года ввели всего 37 тыс. кв. м, в Калининском – 40 тыс. Эти районы застроены давно, приток минимален.
Таким образом, данные обрисовали общую картину: перенасыщенный центр, растущие окраины с низкой конкуренцией и «белые пятна» – крупные МО без единой мастерской. Оставалось превратить это в числовую модель.
Часть 4. Скоринговая модель
Критерии разрабатывал вместе с Claude. Спустя ряд итераций пришли к следующей модели.
Двухэтапная модель
Этап 1 – ранжирование районов (7 критериев, суммарный вес 70%):
| Группа | Критерий | Вес |
|---|---|---|
| Конкуренция | Жителей на одну мастерскую | 20% |
| Конкуренция | Коэффициент выживаемости | 5% |
| Демография | Численность ЦА (30–65 лет) | 15% |
| Демография | Доля женщин трудоспособного возраста | 5% |
| Демография | Рост населения 2018–2025 | 10% |
| Доходы | Средняя зарплата | 10% |
| Инфраструктура | Ввод жилья 2021–2023 | 5% |
Покрытие данных – 70%. Остальные 30% (трафик, транспортная доступность и.т.д) невозможно посчитать из-за отсутствия данных, решили не концентрироваться на этом.
Этап 2 – ранжирование МО внутри топ-районов по конкурентному давлению и «белым пятнам» (МО с населением >50 000 и нулём мастерских).
Результаты скоринга
Топ-5 районов по итоговому баллу:
| Ранг | Район | Балл | Ключевые факторы |
|---|---|---|---|
| 1 | Приморский | 2.57 | Низкая конкуренция, крупнейшая ЦА, активный рост |
| 2 | Пушкинский | 2.43 | Минимум конкурентов, рекордный рост (+33%) |
| 3 | Выборгский | 2.36 | Баланс населения и конкуренции |
| 4 | Красносельский | 2.29 | Мало мастерских, растущий район |
| 4 | Калининский | 2.29 | Высокая выживаемость бизнеса |
На уровне МО выделились «белые пятна» – округа с крупным населением и нулём мастерских: Коломяги (122 тыс.), Парголово (116 тыс.), Красное Село (61 тыс.), Юго-Запад (58 тыс.).
Часть 5. Почему отчёт не решает задачу
Отправил результаты другу.
Он показал знакомому которому нужно было помочь. Реакция: «Интересно, но я остаюсь при своём мнении». И я его понимаю.

Что не так с моделью
Отчёт не учитывает специфику бизнеса. Если заменить «ювелирная мастерская» на «парикмахерская» – результат будет примерно таким же. Модель работает только на уровне демографии.
Мало данных для реального решения. Отсутствуют пешеходный и автомобильный трафик (главный фактор в профессиональных моделях), стоимость аренды по локациям, близость к комплементарным бизнесам (ТЦ, свадебные салоны) и медианный доход домохозяйств – потому что средняя зарплата по предприятиям района не равна доходу людей, которые в этом районе живут.
Малая выборка искажает метрики. На район приходится от 1 до 39 мастерских. Закрытие двух-трёх точек смещает коэффициент выживаемости на 10–15%, что отражает не свойства района, а обстоятельства конкретных людей.
Покрытие модели – 70%. Для грубого отсева 18 → 8 районов этого хватает. Для выбора конкретного адреса – нет.
Что вынес
Ошибки в процессе
Визуализация до анализа. Несколько раз уходил в красивые графики и карты раньше, чем сформулировал вопрос. Делал что-то не для того чтобы достичь цели, а для того чтобы попробовать это сделать. Потратил суммарно месяц на код, который потом не использовал.
Отсутствие плана. Без методологического фреймворка, чёткого плана, легко делать не то, что нужно. Например я только в середине пути обнаружил что данные в росстате за разные года немного не сопадают и оказалось что два МО были переименованы из-за чего и появилось несоответствие.
Исследование вслепую. Хорошо когда есть уже готовый набор данных, но трата времени вслепую – когда данные ещё нужно собрать и обработать, а цель и вопросы не сформулированы – бессмысленная затея.
Организация данных. Без понятной иерархии и организации скриптов и данных, очень легко прийти к хаосу который потом проще выкинуть и начать все сначала. Тем не менее такой подход иногда дает мне понимание “а как лучше сделать”.
Проект “мечты”. Вместо искуственного создания огромного проекта, лучше сконцентрироваться на небольших выполнимых этапах. Иначе от проекта мечты одна усталость и желание перестать им заниматься.
Что сработало
Методология работы. Когда выстроил pipeline (скрипт → CSV → Google Sheets → визуализация), работа пошла в разы быстрее. Появилось чёткое понимание от чего к чему идти, вместо слепого исследования.
Документирование. Документация сыграла важную роль в понимании того что происходит в скриптах и полученных данных. Всякий раз она помогала вернуться в контекст после долгих пауз.
Итерации с паузами. Перерывы по 1–2 недели дали больше, чем непрерывная работа. После каждого возвращался с новым пониманием задачи – именно в паузах приходило осознание, что я делаю не то.
Проект занял ~8 месяцев в свободное время. Код на Python, визуализации в Google Sheets, Tableau. Все данные из открытых источников.